library(tidyverse) # data wrangling and visualizationlibrary(DT) # shows the data tablelibrary(patchwork) # arranging plotslibrary(tidymodels) # modeling (includes broom, yardstick, and other packages)library(knitr) # aesthetic tableslife_exp <-read_csv("https://sta221-fa25.github.io/data/life-expectancy-data.csv") |>rename(life_exp =`Life_expectancy_at_birth`, income_inequality =`Income_inequality_Gini_coefficient`) |>mutate(education =if_else(Education_Index >median(Education_Index), "High", "Low"), education =factor(education, levels =c("Low", "High"))) |>select(Country, life_exp, Health_expenditure, income_inequality)
Learning objectives
By the end of today you will be able to
fit simple linear regression models in R
interpret coefficients in context
analyze the variance
check model fit and interpret in context
Example
The data set comes from Zarulli et al. (2021) who analyze the effects of a country’s healthcare expenditures and other factors on the country’s life expectancy. The data are originally from the Human Development Database and World Health Organization.
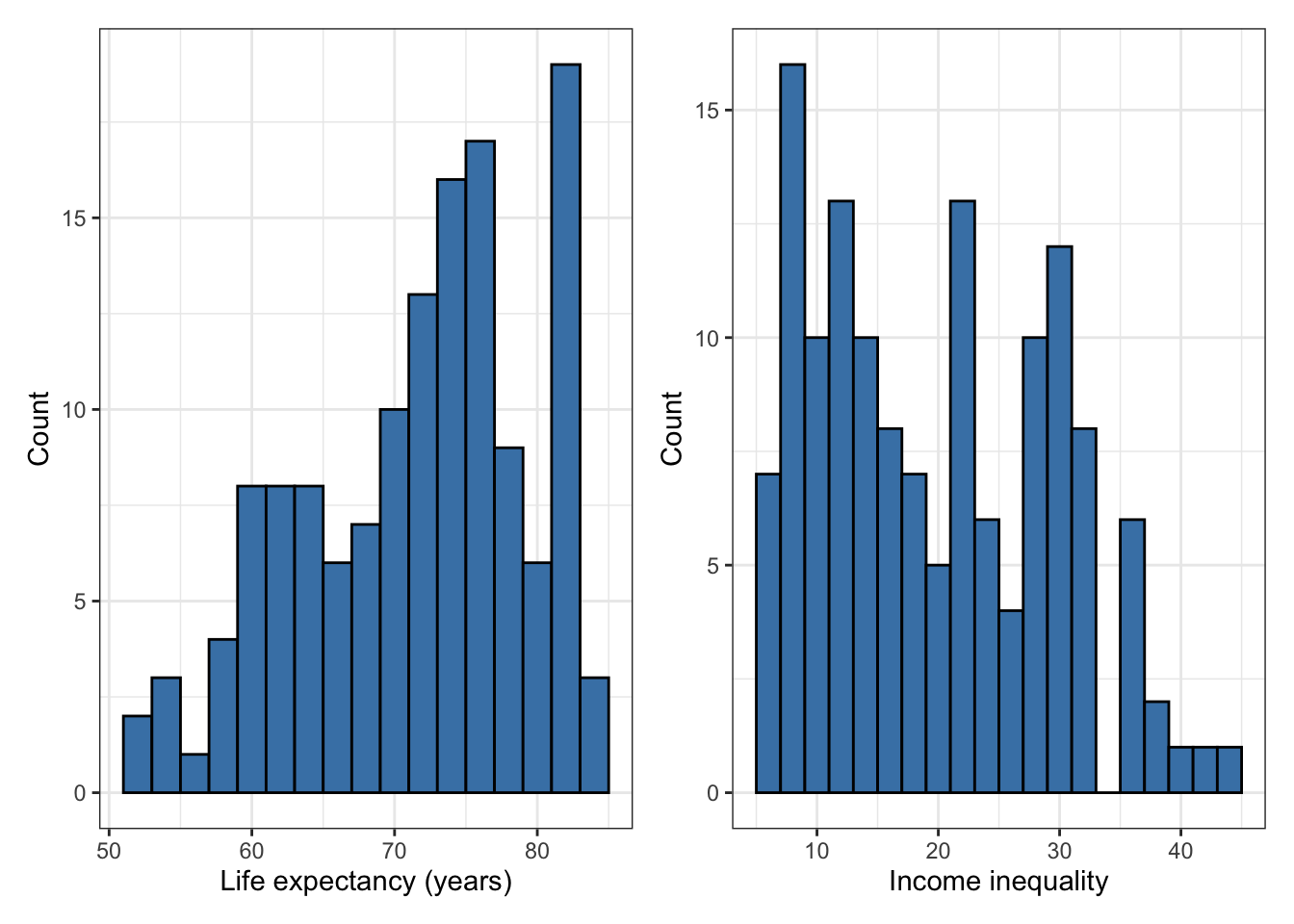
There are 140 countries (observations) in the data set.
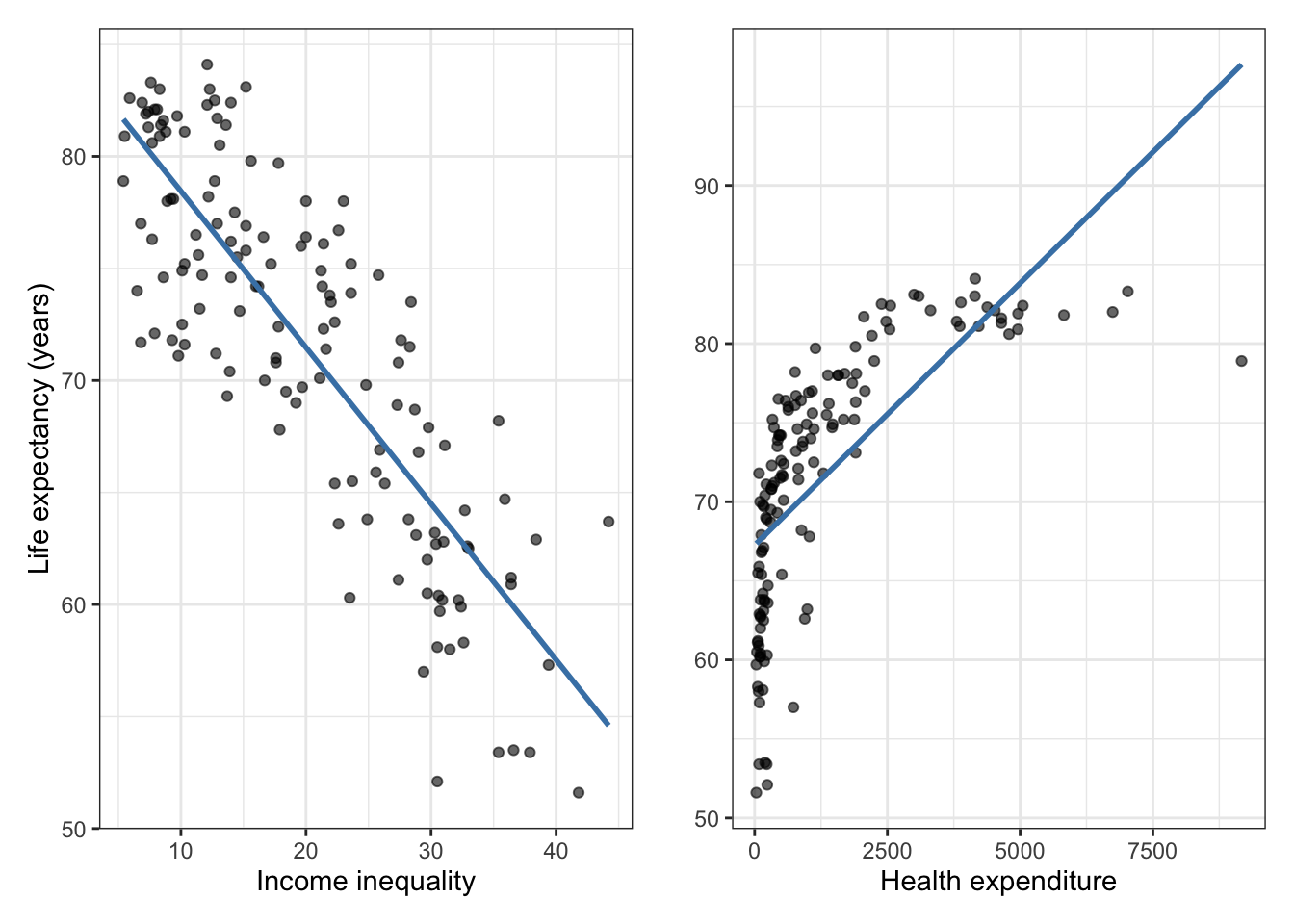
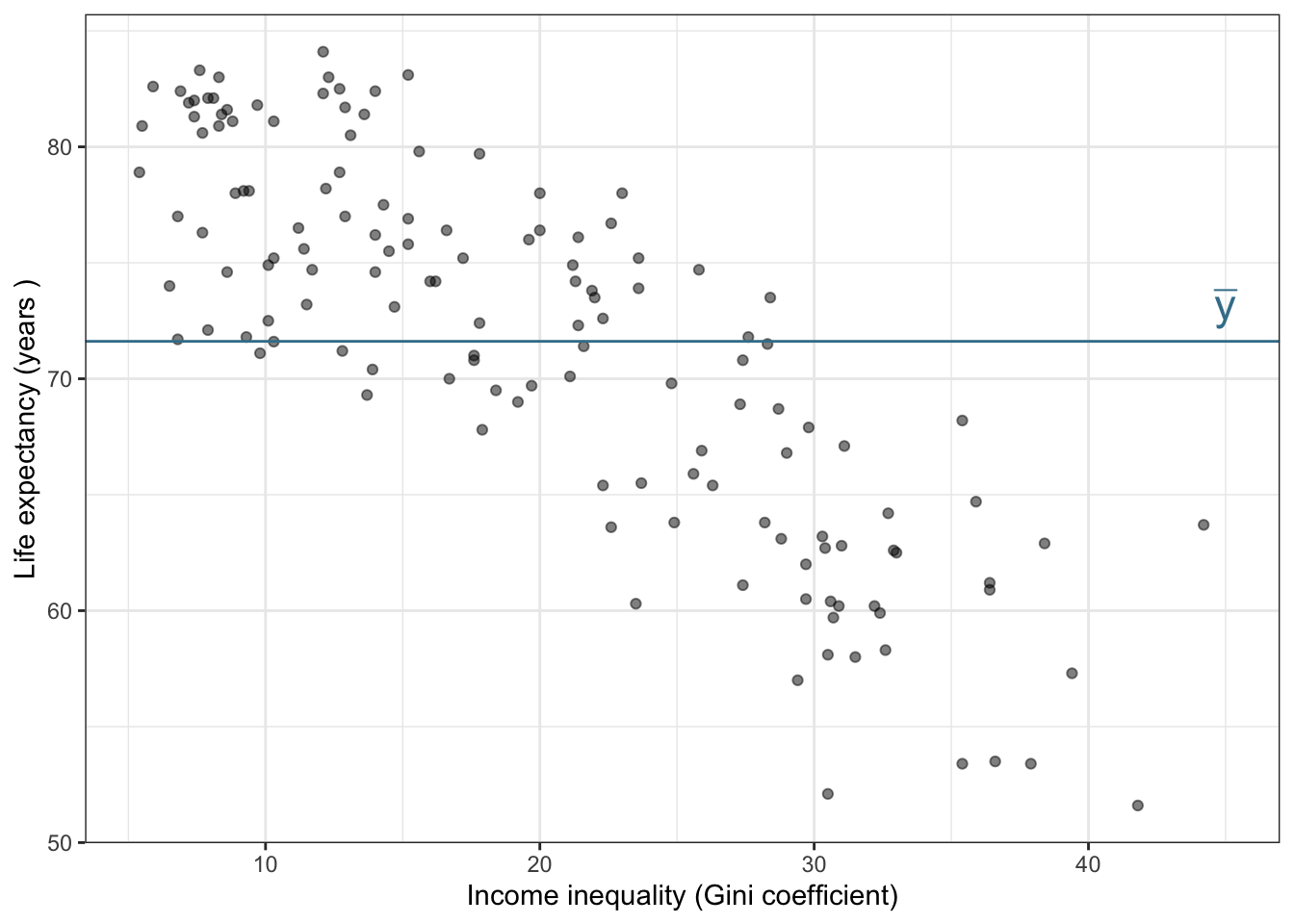
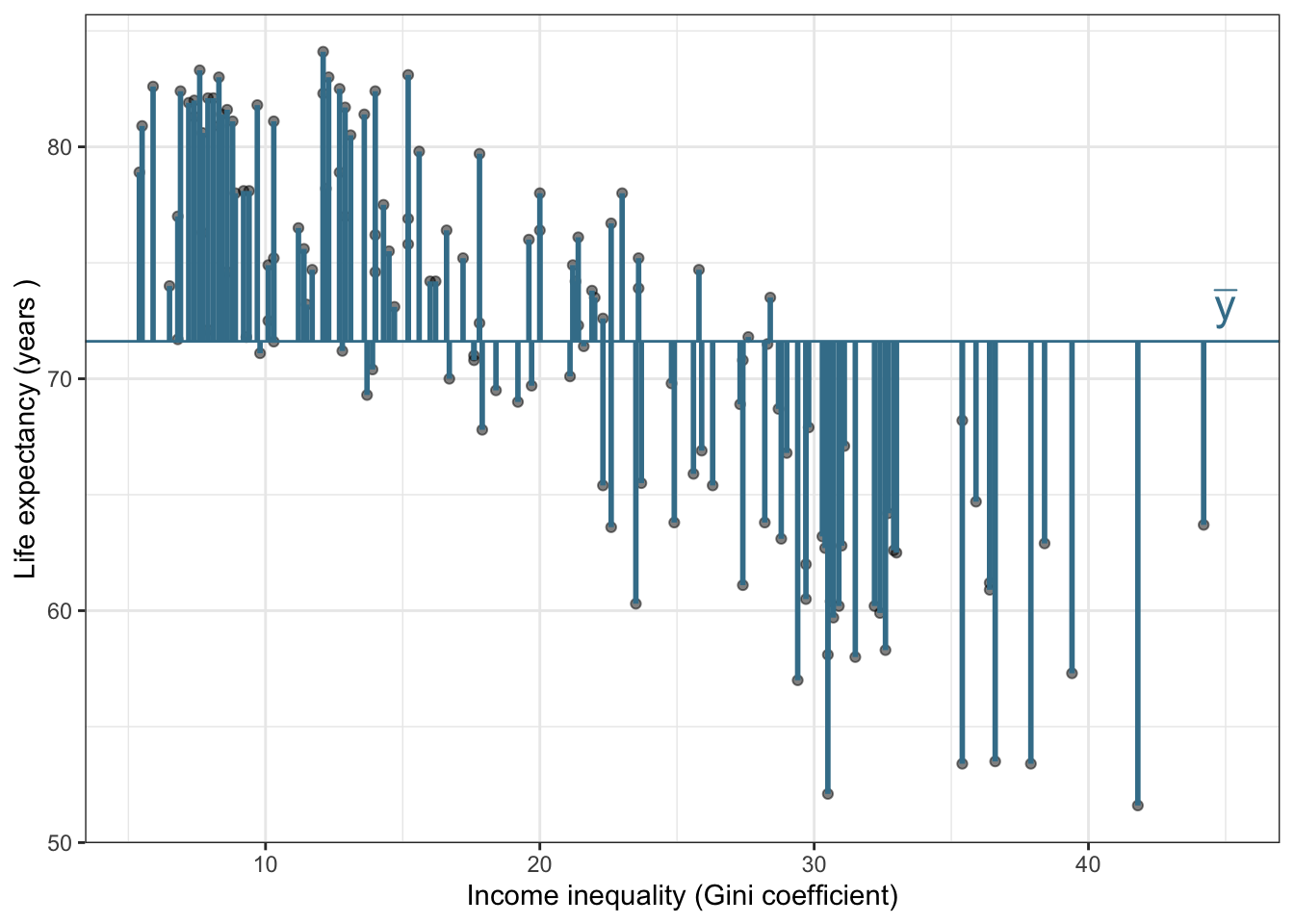
Goal: Use the income inequality in a country to understand variability in the life expectancy.
life_exp: The average number of years that a newborn could expect to live, if he or she were to pass through life exposed to the sex- and age-specific death rates prevailing at the time of his or her birth, for a specific year, in a given country, territory, or geographic area (from the World Health Organization).
income_inequality: Measure of the deviation of the distribution of income among individuals or households within a country from a perfectly equal distribution. A value of 0 represents absolute equality, a value of 100 absolute inequality, based on “Gini coefficient” (from Zarulli et al. (2021)).
health_expenditure: Per capita current spending on healthcare goods and services, expressed in respective currency - international Purchasing Power Parity (PPP) dollar (from the World Health Organization)
# Scatterplot of life expectancy vs income inequalityp1 <-ggplot(life_exp, aes(x = income_inequality, y = life_exp)) +geom_point(alpha =0.6) +geom_smooth(method ="lm", se =FALSE, color ="steelblue") +labs(x ="Income inequality",y ="Life expectancy (years)" ) +theme_bw()# Scatterplot of life expectancy vs health expenditurep2 <-ggplot(life_exp, aes(x = Health_expenditure, y = life_exp)) +geom_point(alpha =0.6) +geom_smooth(method ="lm", se =FALSE, color ="steelblue") +labs(x ="Health expenditure",y ="" ) +theme_bw()# Display plots side by side; uses patchwork pacakgep1 + p2
Ordinary least squares regression in R
Template
To fit a model by OLS linear regression, we use the lm function. The arguments look as follows:
lm(y ~ x, data = data_frame)
In words, we “regress y on x” where “y” and “x” are column names in the data frame “data_frame”.
For our data
# income inequality modelmodel_ii =lm(life_exp ~ income_inequality, data = life_exp)# health expenditure modelmodel_he =lm(life_exp ~ Health_expenditure,data = life_exp)
Q: why is Health_expenditure capitalized, but income_inequality is not?
A: That’s how they are named in the data! See the column names: names(life_exp).
Put results in a more aesthetic table using kable from the knitr package:
model_ii |>tidy() |>kable(digits =3)
term
estimate
std.error
statistic
p.value
(Intercept)
85.420
0.855
99.877
0
income_inequality
-0.697
0.039
-17.961
0
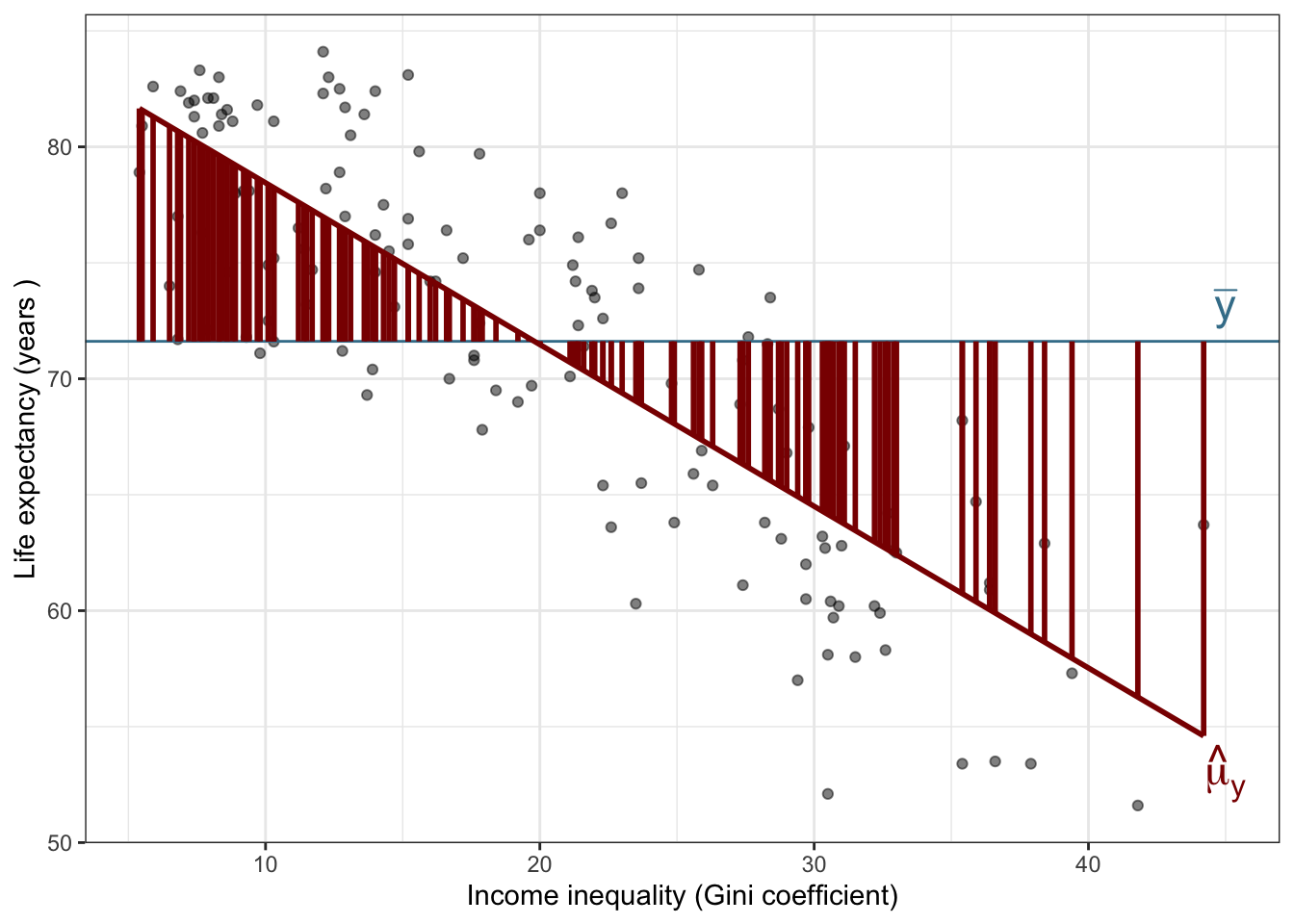
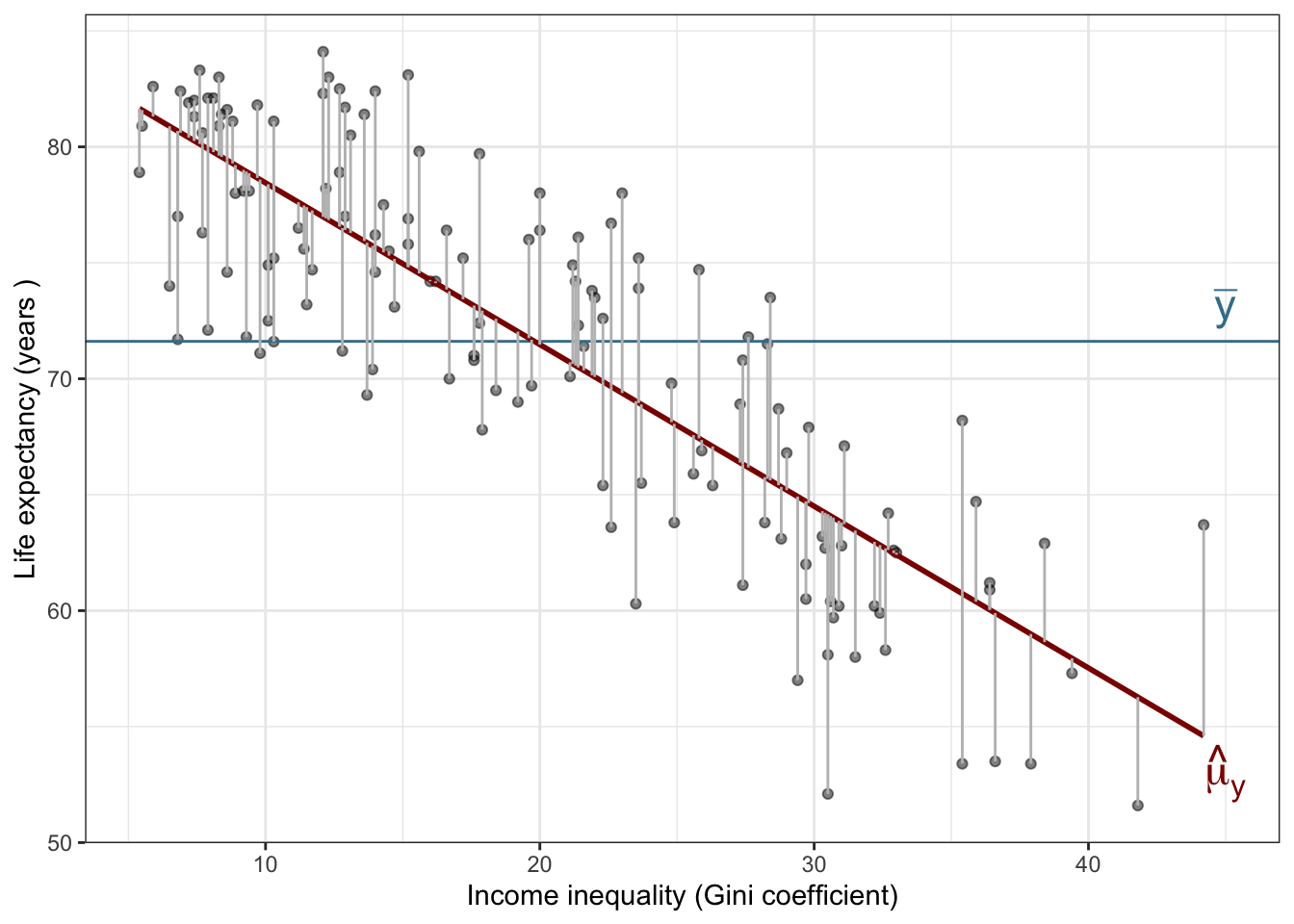
The fitted regression model:
\[
\hat{y_i} = 85.420 - 0.697 x_i
\]
Interpretation
The intercept estimate \(\hat{\beta}_0\) is in units of the response variable. It is the expected value of the response variable when the predictor is set to 0.
The estimate of the slope coefficient, \(\hat{\beta}_1\) is measured in the units of the response variable per unit of the explanatory variable.
Use the rmse() function from the yardstick package (part of tidymodels)
rmse(life_exp_aug, truth = life_exp, estimate = .fitted)
# A tibble: 1 × 3
.metric .estimator .estimate
<chr> <chr> <dbl>
1 rmse standard 4.40
Finding \(R^2\) in R
Use the rsq() function from the yardstick package (part of tidymodels)
rsq(life_exp_aug, truth = life_exp, estimate = .fitted)
# A tibble: 1 × 3
.metric .estimator .estimate
<chr> <chr> <dbl>
1 rsq standard 0.700
Alternatively, use glance() to construct a single row summary of the model fit, including \(R^2\):
glance(model_ii)$r.squared
[1] 0.7003831
References
Zarulli, Virginia, Elizaveta Sopina, Veronica Toffolutti, and Adam Lenart. 2021. “Health Care System Efficiency and Life Expectancy: A 140-Country Study.” Edited by Srinivas Goli. PLOS ONE 16 (7): e0253450. https://doi.org/10.1371/journal.pone.0253450.