View libraries and data sets used in these notes
library(tidyverse)
library(DT)
weather <-
read_csv("https://sta221-fa25.github.io/data/rdu-weather-history.csv") %>%
arrange(date)library(tidyverse)
library(DT)
weather <-
read_csv("https://sta221-fa25.github.io/data/rdu-weather-history.csv") %>%
arrange(date)By the end of the day you should be able to explain the following concepts:
This data set contains Raleigh Durham International Airport weather data pulled from the NOAA web service between September 01 and September 30, 2021. The data were sourced from https://catalog.data.gov/ August 28, 2025.
We’ve recorded 30 observations of two measurements. We are interested in the association between these two measurements.
We’ll call the minimum daily temperature measurement “x” and the maximum daily temperature “y”.
| Variable | Explanation |
|---|---|
| \(y\) | The outcome variable. Also called “response” or “dependent variable”. In prediction tasks, this is the variable we are interested in predicting. |
| \(x\) | The predictor. Also called “covariate”, “feature”, or “independent variable”. |
How are \(x\) and \(y\) associated?
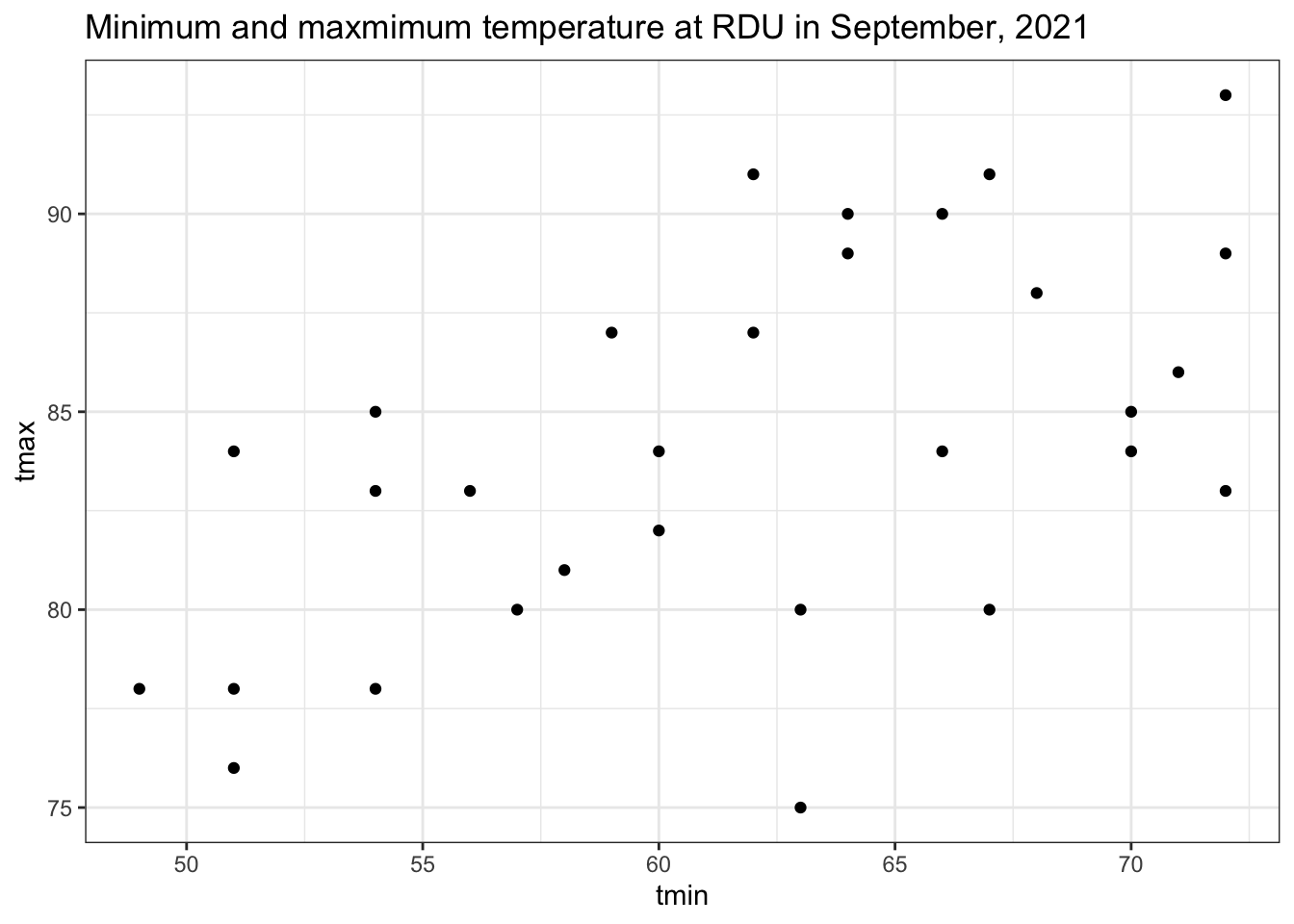
weather %>%
ggplot(aes(x = tmin, y = tmax)) +
geom_point() +
labs(title = "Minimum and maxmimum temperature (F) at RDU in September, 2021") +
theme_bw()Notice: visualized this way, each of the thirty data points, \((x_i, y_i)\), is an element of two-dimensional space.
\(cov(x, y) = \frac{1}{n-1}\sum_{i =1}^n (x_i - \bar{x}) (y_i - \bar{y})\) \(^*\)
\(^*\) Note that we divide by \(n-1\) when computing the sample covariance
x = weather %>%
select(tmin) %>%
pull()
y = weather %>%
select(tmax) %>%
pull()
cov(x, y)[1] 18.68736sum((x - mean(x)) * (y - mean(y))) / (30 - 1)[1] 18.68736# compute covariance of true temperature measurement
weather %>%
mutate(temp_min_true = tmin + 2,
temp_max_true = tmax + 2) %>%
summarize(cov(temp_min_true, temp_max_true)) %>%
pull()[1] 18.68736Covariance is location invariant.
# compute the covariance between temperature in celsius
weather %>%
mutate(temp_min_c = (tmin - 32) * 5 / 9,
temp_max_c = (tmax - 32) * 5 / 9) %>%
summarize(cov(temp_min_c, temp_max_c)) %>%
pull()[1] 5.767703Covariance is not scale invariant. That is, covariance does depend on the scale of the measurements.
\(cor(x, y) = \frac{\sum_{i=1}^n (x_i - \bar{x}) (y_i - \bar{y})}{\left(\sum (x_i - \bar{x})^2 \sum (y_i - \bar{y})^2\right)^{1/2}}\)
More concisely, we may write
\(cor(x, y) = \frac{S_{xy}}{S_{xx}^{1/2} S_{yy}^{1/2}}\)
# correlation in Farenheit vs Celsi
# compute the covariance between temperature in celsius
weather %>%
mutate(temp_min_c = (tmin - 32) * 5 / 9,
temp_max_c = (tmax - 32) * 5 / 9) %>%
summarize(cor_F = cor(tmin, tmax),
cor_C = cor(temp_min_c, temp_max_c))# A tibble: 1 × 2
cor_F cor_C
<dbl> <dbl>
1 0.554 0.554Show \(cor(x, y) = cor(ax + b, cy + d)\).
Let \[ \begin{aligned} x^* &= ax_i + b,\\ y^* &= cx_i + d, \end{aligned} \]
then we want to prove that \(cor(x, y) = cor(x^*, y^*)\).
\[ \begin{aligned} cor(x^*, y^*) &= \frac{\sum(ax_i + b - a\bar{x} - b)(cy_i + d - c\bar{y} - d)}{\sqrt{ \sum (ax_i + b - a\bar{x} - b)^2 \sum (cy_i + d - c\bar{y} - d)^2 } }\\ &= \frac{ac \sum(x_i -\bar{x})(y_i - \bar{y})}{ ac \sqrt{\sum (ax_i + b - a\bar{x} - b)^2 \sum (cy_i + d - c\bar{y} - d)^2 } }\\ &= \frac{ S_{xy}}{\sqrt{S_{xx} S_{yy}} } \end{aligned} \]
Correlation is location and scale invariant!
Additional facts about correlation:
\(g\) is a monotonic function iff \(x \leq y\) implies \(g(x) \leq g(y)\)
Show by example that correlation is not invariant to monotonic transformations.
set.seed(221)
x = c(1:10)
logx = log(x)
y = rnorm(10)
cor(x, y)[1] -0.1757986cor(logx, y)[1] -0.2686214set.seed(221)
x = c(1:5)
y= x + rnorm(5)
plot(x, y)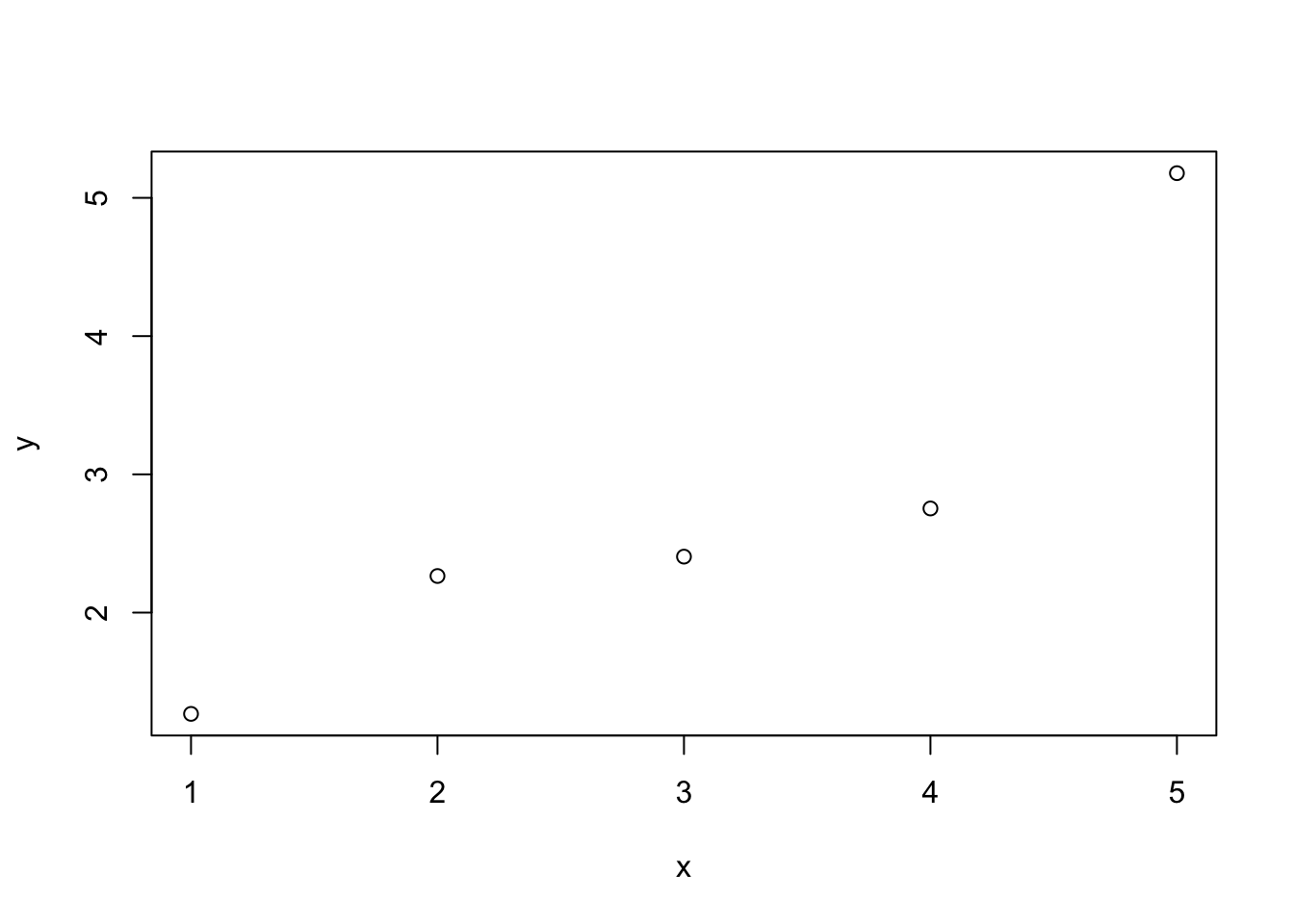
cor(x, y)[1] 0.9042223x2 = c(x, 0)
y2 = c(y, 20)
plot(x2, y2)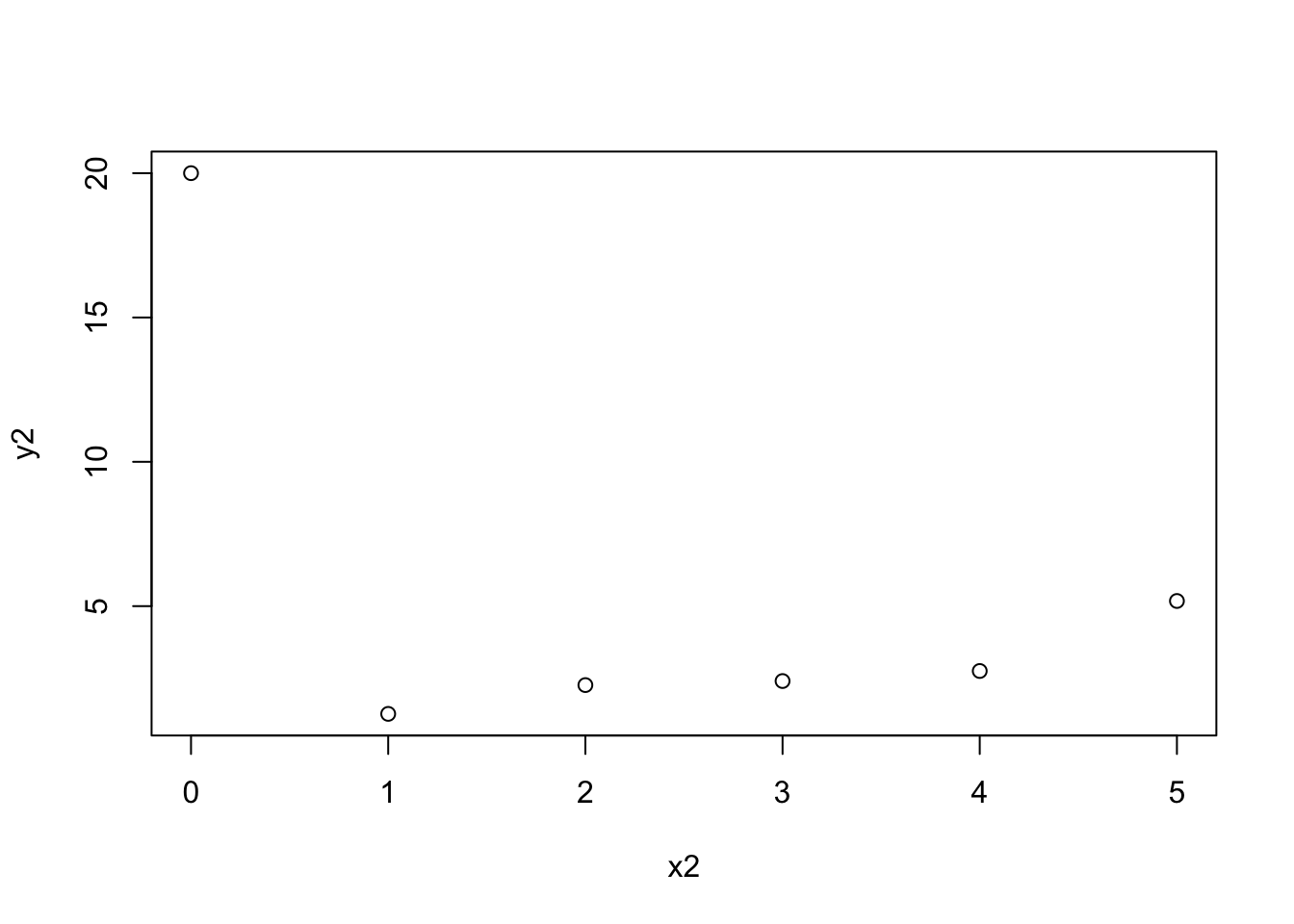
cor(x2, y2)[1] -0.5195233Correlation is bounded between -1 and 1.
Show that \(|cor(x, y)| \leq 1\)
Cauchy-Schwarz inequality:
Let \(u\) and \(v\) be vectors of dimension \(n\), then
\[ |u^T v|^2 \leq (u^Tu) (v^Tv). \] To prove that \(\|cor(x,y)\| \leq 1\), let \(u = x - \bar{x}\) and let \(v = y - \bar{y}\).
Notice that the dimension of a vector inner product, e.g. \(u^Tv\) is \(1 \times 1\), in other words, it is a “scalar”, a number.
x = -10:10
y = x^2
plot(x, y)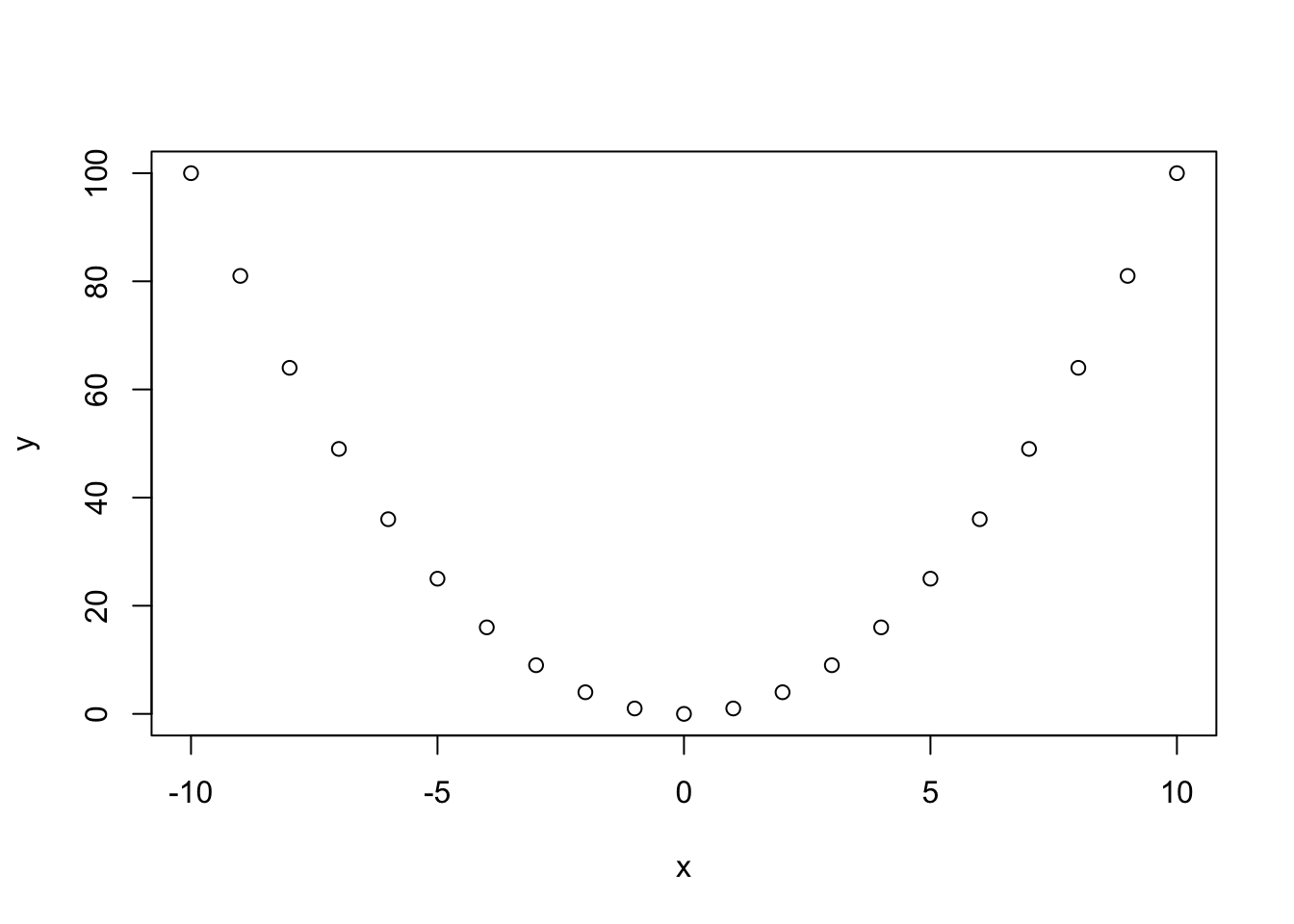
cor(x, y) [1] -4.786989e-17x = -10:10
y = x
plot(x, y)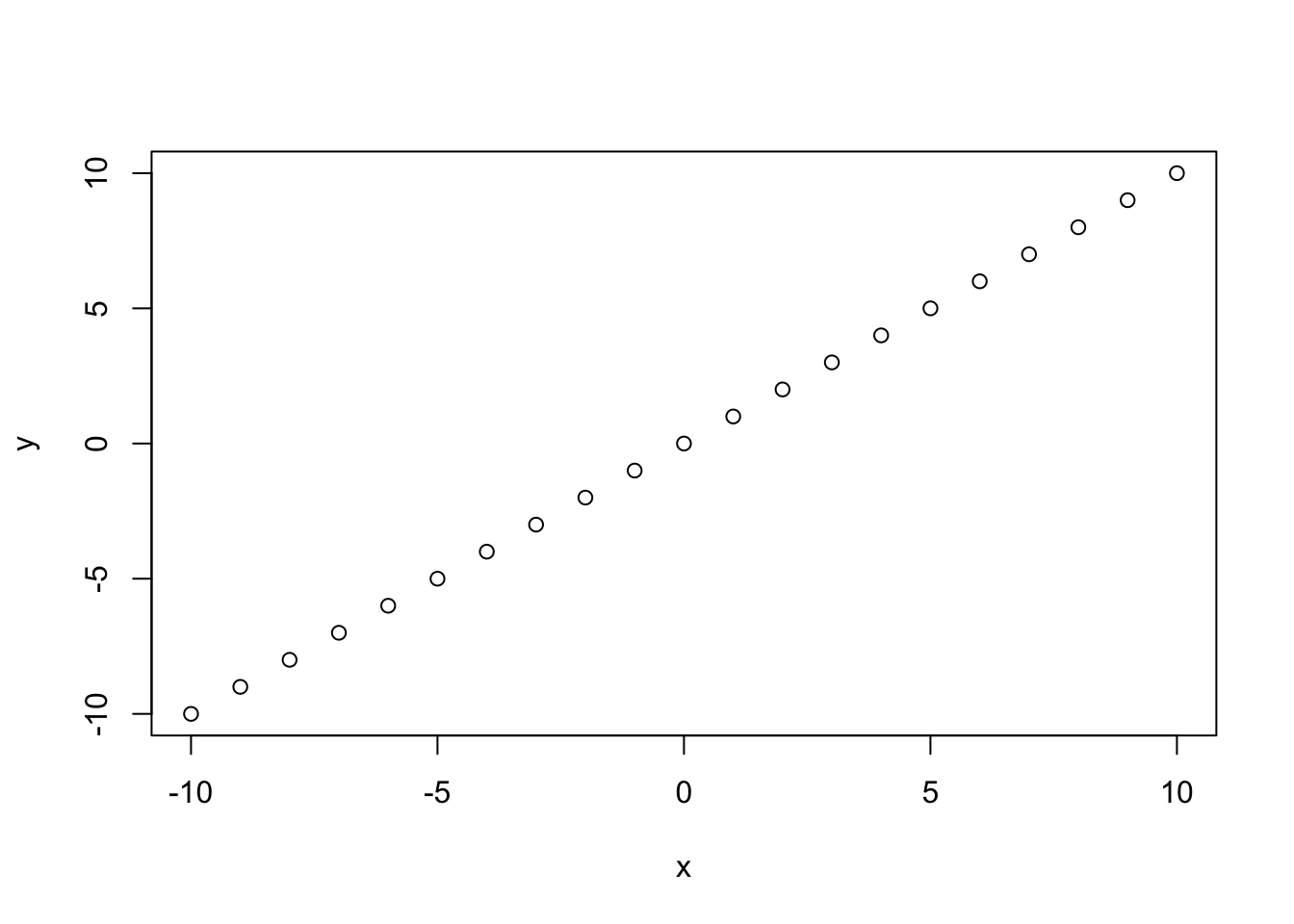
cor(x, y)[1] 1Since correlation is related to a linear relationship between the data, strong correlation implies that
\[ y_i = \beta_0 + \beta_1 x_i + \epsilon_i \]
Check out the interactive regression web app here:
https://seeing-theory.brown.edu/regression-analysis/index.html#section1
| Symbol | Description |
|---|---|
| \(y\) | The response variable. Also called the “outcome” or “dependent variable”. |
| \(x\) | A covariate. Also called the “predictor”, “feature” or “independent variable”. |
| \(\beta_0, \beta_1\) | These are population parameters, i.e. fixed and unknown constants. |
| \(\hat{\beta}_0, \hat{\beta}_1\) | Estimates of \(\beta_0, \beta_1\) based on a sample. |
| \(\hat{y}\) | The prediction outcome. \(\hat{y} = \hat{\beta_0} + \hat{\beta_1} x\). May also be referred to as the “fitted regression model”. |
| \(\epsilon\) | The error. Defined by the regression equation: \(\epsilon = y - \beta_0 - \beta_1 x\). |
| \(\hat{\epsilon}\) or \(e\) | The residual, i.e. the difference between the outcome and the fitted model. Defined as \(y - \hat{y}\), or equivalently, \(y - \hat{\beta_0} - \hat{\beta_1}x\) |